
Data Integration is the process of combining data from different sources to provide a unified, consistent view of enterprise data across systems.
It eliminates silos, improves data accessibility, supports real-time analytics, and enables better decision-making by providing a single source of truth.
Inconsistent formats, real-time synchronization, scalability, and maintaining data quality are common hurdles during integration.
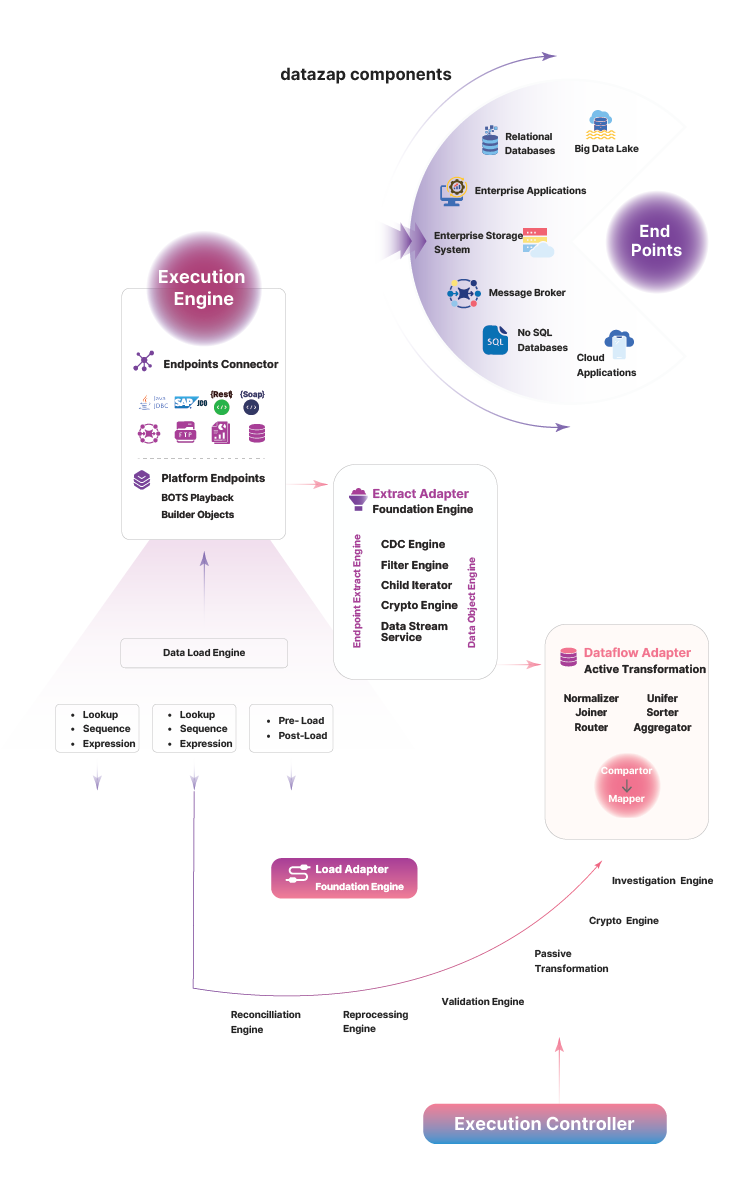
ChainSys' dataZap offers pre-built connectors, drag-and-drop configurations, and real-time orchestration to ensure fast, reliable, and secure integrations across cloud and on-prem systems.

Seamless Data Management & AI-Driven Insights – Empowering Your Enterprise with ChainSys Smart Solutions.







Unlock the full potential of your enterprise data with ChainSys’ Enterprise Data Management (EDM) solutions. Our Smart Data Platform ensures seamless data integration, governance, quality, and analytics, empowering businesses with trusted, high-quality data for smarter decision-making. With AI-driven automation, metadata intelligence, and a no-code/low-code approach, ChainSys simplifies data complexity, enhances compliance, and accelerates digital transformation. Turn your data into a strategic asset with ChainSys!

Migrate your enterprise data with confidence using ChainSys’ AI-driven Data Migration solutions. Our Smart Data Platform ensures a seamless, automated, and secure transition across legacy and modern systems while maintaining data integrity and minimizing downtime. With a metadata-driven, no-code/low-code approach, achieve faster, cost-effective migrations with repeatability and compliance. Move your data effortlessly and accelerate your digital transformation journey!

Ensure your enterprise operates with trusted, high-quality data using ChainSys’ Data Quality solutions. Leverage AI-powered cleansing, deduplication, validation, and enrichment to eliminate errors, inconsistencies, and redundancies. With real-time monitoring, rule-based automation, and intuitive dashboards, drive better decision-making and regulatory compliance. Clean data is powerful data—make every insight count!

Achieve complete data transparency, security, and compliance with ChainSys’ Data Governance solutions. Define and enforce policies, manage access controls, and ensure regulatory compliance with AI-driven automation. Our Smart Data Platform provides metadata-driven governance, enabling organizations to gain trust, mitigate risks, and unlock the true value of their data assets. Govern with confidence—govern with ChainSys!

Supercharge your data strategy with Active Metadata Management from ChainSys. Our AI-powered solution continuously captures, enriches, and operationalizes metadata for improved visibility, lineage tracking, and intelligent automation. Gain actionable insights, accelerate digital initiatives, and enhance collaboration with metadata-driven intelligence. Turn metadata into a competitive advantage with ChainSys!

Reduce storage costs, ensure compliance, and maintain easy access to historical data with ChainSys’ Data Archival solutions. Our automated, scalable, and policy-driven approach enables seamless data retirement while ensuring on-demand retrieval and compliance adherence. Optimize performance, free up resources, and keep your data ecosystem lean and efficient!
Transform raw data into actionable intelligence with ChainSys’ Data Analytics solutions. Leverage AI/ML-driven insights, real-time reporting, and intuitive dashboards to gain deeper business understanding and drive innovation. With seamless data integration and advanced visualization, empower your teams with data-driven decision-making for a competitive edge!

Break down data silos and enable seamless connectivity with ChainSys’ Data Integration solutions. Our metadata-driven, AI-powered platform ensures smooth, real-time data flow across cloud, on-premise, and hybrid environments. Gain unified, consistent, and reliable data across your enterprise for enhanced collaboration and efficiency. Connect, unify, and thrive with ChainSys!

Protect your most valuable asset—your data—with ChainSys’ Data Security solutions. Ensure enterprise-wide data protection, encryption, access controls, and regulatory compliance with AI-driven monitoring and proactive threat detection. Mitigate risks, prevent breaches, and safeguard sensitive information with confidence. Your data, your rules—stay secure with ChainSys!

Achieve a single source of truth with ChainSys’ Master Data Management (MDM) solutions. Establish consistency, eliminate duplicates, and ensure accuracy across your enterprise with a governed, AI-driven approach. Enable seamless collaboration, enhance business operations, and gain a trusted foundation for all your data-driven initiatives. Master your data, master your business with ChainSys!



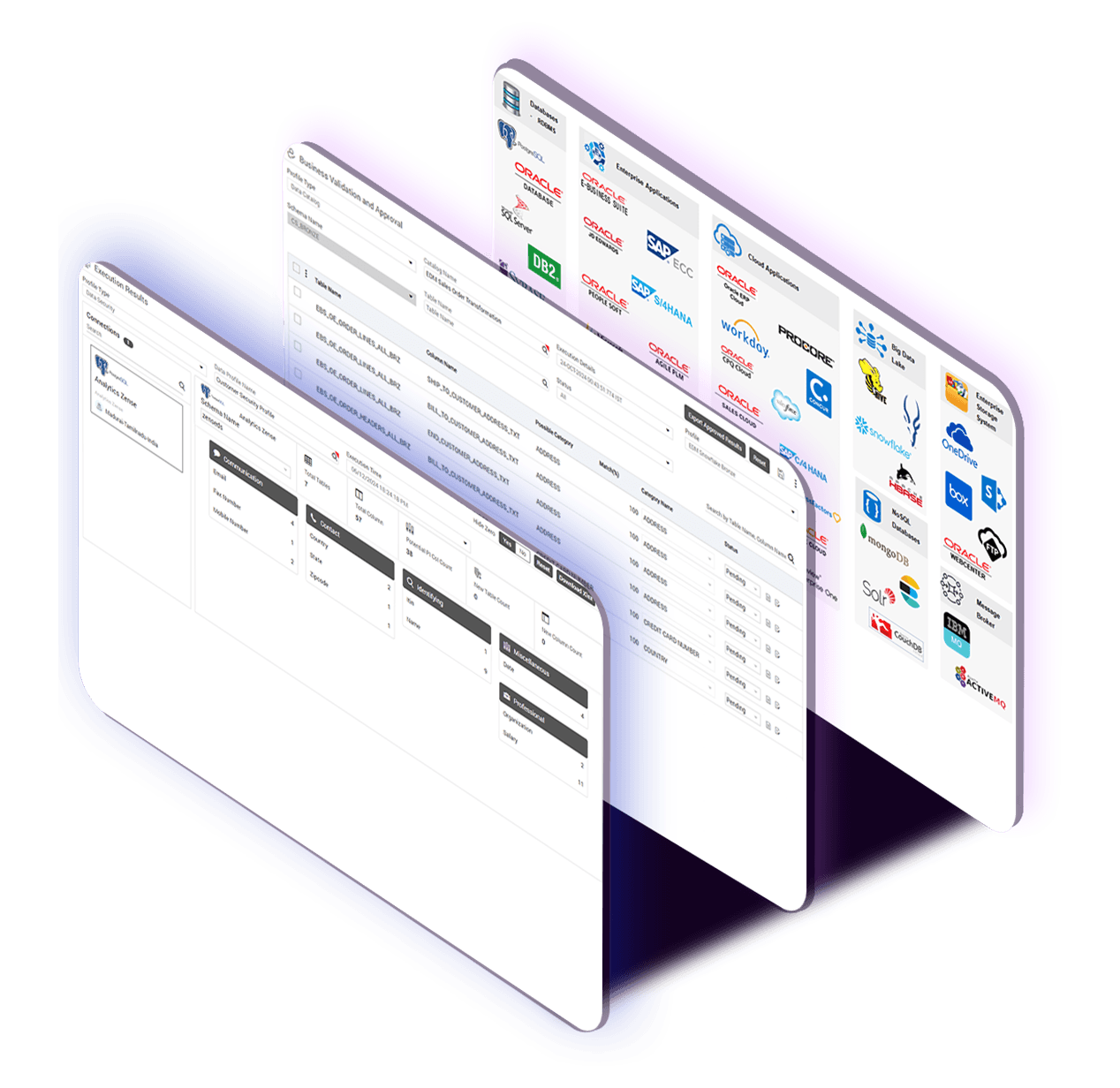
ChainSys offers an extensive library of pre-built connectors for all major ERP, CRM, and other enterprise systems. It also supports custom API integration, allowing businesses to connect virtually any application or database.

ChainSys enables efficient Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) processes, ensuring that data is cleansed, validated, and optimized before it is integrated into target systems.

Whether you need real-time updates or batch processing, ChainSys supports both, ensuring that your data stays in sync according to your operational needs.
ChainSys provides powerful tools to transform, map, and enrich data as it moves between systems, ensuring consistency and accuracy.

Ensure the accuracy, completeness, and consistency of your integrated data with robust data quality management capabilities, including validation and deduplication.

ChainSys allows you to track, manage, and maintain metadata associated with your data integration processes, ensuring that data remains well-documented and traceable.

ChainSys prioritizes data security and ensures compliance with industry standards and regulations through advanced encryption, audit trails, and access controls.

With embedded data governance features, ChainSys enables businesses to define, enforce, and monitor data policies, ensuring proper management and usage of integrated data.

ChainSys AMM automatically collects and catalogs metadata from various sources, including databases, data warehouses and cloud platforms. This continuous harvesting ensures that metadata is always up-to-date.

The platform provides comprehensive data lineage capabilities, allowing organizations to visualize the entire data journey from source to consumption. This helps in understanding dependencies and identifying potential issues.

By actively using metadata, ChainSys AMM supports automated data quality checks and validation processes. It ensures that data adheres to predefined quality standards before being used in critical operations.
ChainSys’s AMM uses metadata to enforce data governance policies automatically. It includes role-based access controls, policy enforcement, and compliance monitoring, ensuring that data is managed according to organizational rules and regulations.

The AMM seamlessly integrates with enterprise data catalogs, enabling a unified view of all data assets. This integration facilitates better data discovery, tagging, and collaboration across teams.

Tailored migration workflows allow organizations to define specific rules for data mapping, transformation, and validation based on business needs.
ChainSys offers an extensive library of pre-built connectors for all major ERP, CRM, and other enterprise systems. It also supports custom API integration, allowing businesses to connect virtually any application or database.
ChainSys enables efficient Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) processes, ensuring that data is cleansed, validated, and optimized before it is integrated into target systems.
Whether you need real-time updates or batch processing, ChainSys supports both, ensuring that your data stays in sync according to your operational needs.
ChainSys provides powerful tools to transform, map, and enrich data as it moves between systems, ensuring consistency and accuracy.
Ensure the accuracy, completeness, and consistency of your integrated data with robust data quality management capabilities, including validation and deduplication.
ChainSys allows you to track, manage, and maintain metadata associated with your data integration processes, ensuring that data remains well-documented and traceable.
ChainSys prioritizes data security and ensures compliance with industry standards and regulations through advanced encryption, audit trails, and access controls.
With embedded data governance features, ChainSys enables businesses to define, enforce, and monitor data policies, ensuring proper management and usage of integrated data.
ChainSys AMM automatically collects and catalogs metadata from various sources, including databases, data warehouses and cloud platforms. This continuous harvesting ensures that metadata is always up-to-date.
The platform provides comprehensive data lineage capabilities, allowing organizations to visualize the entire data journey from source to consumption. This helps in understanding dependencies and identifying potential issues.
By actively using metadata, ChainSys AMM supports automated data quality checks and validation processes. It ensures that data adheres to predefined quality standards before being used in critical operations.

ChainSys’s AMM uses metadata to enforce data governance policies automatically. It includes role-based access controls, policy enforcement, and compliance monitoring, ensuring that data is managed according to organizational rules and regulations.
The AMM seamlessly integrates with enterprise data catalogs, enabling a unified view of all data assets. This integration facilitates better data discovery, tagging, and collaboration across teams.
The platform provides analytics and reporting on metadata, allowing organizations to monitor data quality trends, governance adherence, and usage patterns in real time.
Break down silos and build connected systems with ChainSys. Enable smart, automated, and scalable integration across your digital ecosystem.
Ready to connect your enterprise?
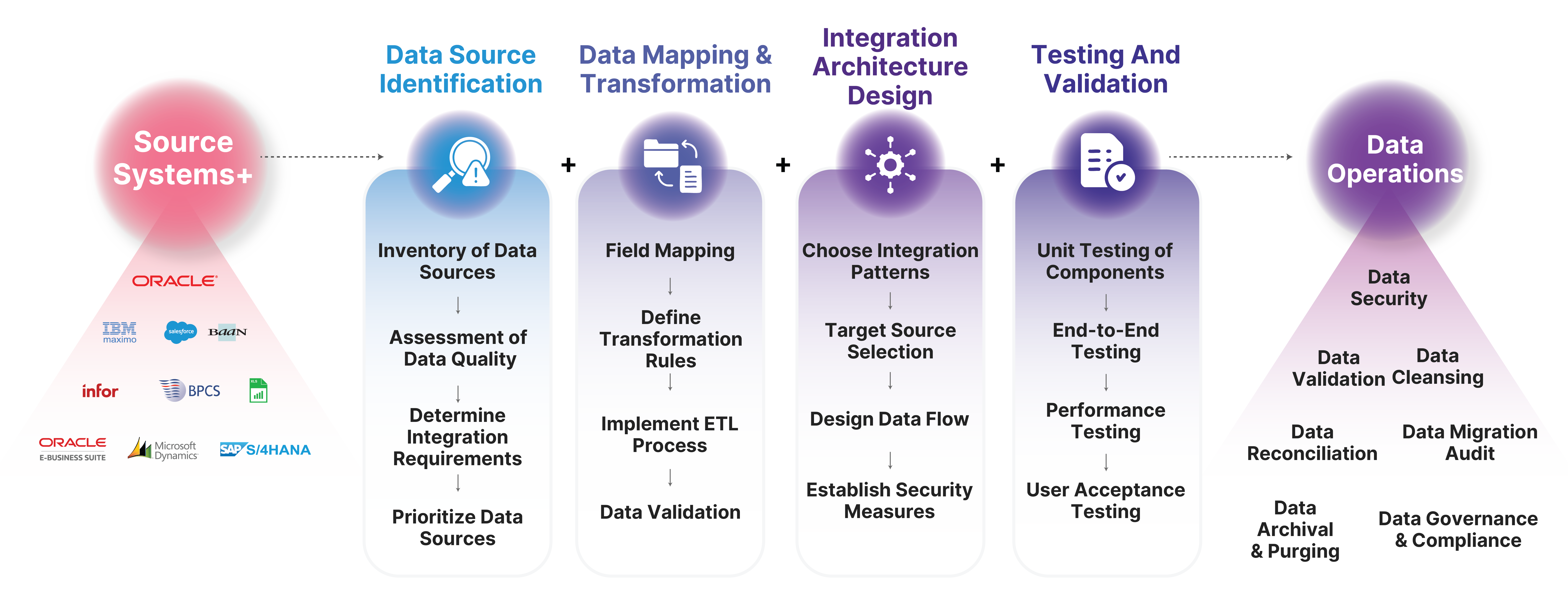
ChainSys Data Integration eliminates silos by ensuring that data moves fluidly between systems, allowing for cohesive operations and decision-making.
Automating the integration of data across multiple platforms minimizes manual interventions, reduces errors, and accelerates business processes.
Achieve a single source of truth across your enterprise by integrating data from disparate systems, enabling more accurate and consistent reporting and analytics.
Connect effortlessly to 200+ endpoints across enterprise and cloud.


























































































Our platform is meticulously designed to provide a seamless integration experience, ensuring your data flows effortlessly across a diverse array of applications. Experience the unparalleled ease of connecting with over 200 applications effortlessly.

The scope undertaken was the implementation of an integration platform (dataZap) to centralize and interface business data across multiple end points into Oracle EBS applications from fifteen locations...

Implementing an Enterprise Data Management solution on Hadoop Impala data lake as the central data warehouse.

This project was aimed at integrating data flow between their project management system Procore and SAP ECC...

An enterprise-wide integration platform was introduced to centralize all integrations flowing across the business.

ChainSys's solutions increase data discovery efficiency by 75%, enabling quicker access to relevant data assets and reducing the time spent on manual searches.
With ChainSys's pre-built connectors and templates, businesses can implement active metadata management solutions 50% faster than traditional methods.
ChainSys has successfully executed 500+ global data integration projects, ensuring flawless connectivity across complex enterprise environments.
ChainSys's solutions increase data discovery efficiency by 75%, enabling quicker access to relevant data assets and reducing the time spent on manual searches.
With ChainSys's pre-built connectors and templates, businesses can implement active metadata management solutions 50% faster than traditional methods.
With over 1,500+ pre-built connectors, ChainSys accelerates integration with major enterprise systems like SAP, Oracle, Salesforce, and Microsoft, reducing development time by up to 50%.
ChainSys's solutions increase data discovery efficiency by 75%, enabling quicker access to relevant data assets and reducing the time spent on manual searches.
With ChainSys's pre-built connectors and templates, businesses can implement active metadata management solutions 50% faster than traditional methods.
ChainSys's solutions increase data discovery efficiency by 75%, enabling quicker access to relevant data assets and reducing the time spent on manual searches.
With ChainSys's pre-built connectors and templates, businesses can implement active metadata management solutions 50% faster than traditional methods.
ChainSys's solutions increase data discovery efficiency by 75%, enabling quicker access to relevant data assets and reducing the time spent on manual searches.
With ChainSys's pre-built connectors and templates, businesses can implement active metadata management solutions 50% faster than traditional methods.







Unlock the potential of your data with dataZap, a comprehensive solution for Data and Setup Migration, Integration, and Reconciliation. Seamlessly manage your data lifecycle, ensuring a smooth and error-free transition. Leverage advanced archiving capabilities to streamline storage and optimize performance, all while maintaining data integrity.

Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.



























